
{kind=link}
Οι ερευνητές της Apple ανέπτυξαν έναν νέο τρόπο εκπαίδευσης μοντέλων τεχνητής νοημοσύνης για τη δημιουργία λεζάντας εικόνων, ο οποίος παρέχει πιο ακριβείς, λεπτομερείς περιγραφές, ενώ χρησιμοποιεί πολύ μικρότερα μοντέλα. Εδώ είναι οι λεπτομέρειες.
Ένα νέο μοντέλο θα μπορούσε να επιταχύνει την εκπαίδευση μελλοντικών πολυτροπικών AI
Σε μια νέα μελέτη με τίτλο RubiCap: Εκμάθηση ενίσχυσης καθοδηγούμενη από ρουμπρίκα για πυκνούς λεζάντες εικόνωνμια ομάδα Ερευνητών της Apple συνεργάστηκε με το Πανεπιστήμιο του Wisconsin-Madison για να αναπτύξει ένα νέο πλαίσιο για ένα πυκνό μοντέλο υπότιτλων εικόνων, αποδίδοντας αποτελέσματα τελευταίας τεχνολογίας σε πολλαπλά σημεία αναφοράς.
Οι πυκνές λεζάντες εικόνων είναι το έργο της δημιουργίας λεπτομερών περιγραφών σε επίπεδο περιοχής για όλα όσα συμβαίνουν μέσα σε μια εικόνα, αντί για μια ενιαία συνολική περίληψη.
Με άλλα λόγια, προσδιορίζει πολλαπλά στοιχεία και περιοχές σε μια εικόνα και τα περιγράφει με λεπτές λεπτομέρειες, με αποτέλεσμα μια πολύ πιο πλούσια κατανόηση της σκηνής από μια συνολική περιγραφή.
Ακολουθούν μερικά παραδείγματα από το αρχικό χαρτί με λεζάντες του Στάνφορντ, DenseCap: Πλήρως συνελικτικά δίκτυα τοπικής προσαρμογής για πυκνούς υπότιτλους:

Η πυκνή λεζάντα εικόνων μπορεί να χρησιμοποιηθεί για μια ποικιλία εργασιών, όπως η εκπαίδευση μοντέλων γλώσσας όρασης και κειμένου σε εικόνα. Όταν εφαρμόζεται σε λειτουργίες που αντιμετωπίζουν οι χρήστες, μπορεί να βελτιώσει την αναζήτηση εικόνων και ακόμη και τα εργαλεία προσβασιμότητας.
Το πρόβλημα, σύμφωνα με τους ερευνητές, είναι ότι οι τρέχουσες προσεγγίσεις που βασίζονται στην τεχνητή νοημοσύνη για την εκπαίδευση μοντέλων με πυκνές λεζάντες εικόνων τείνουν να υπολείπονται με σημαντικούς τρόπους:
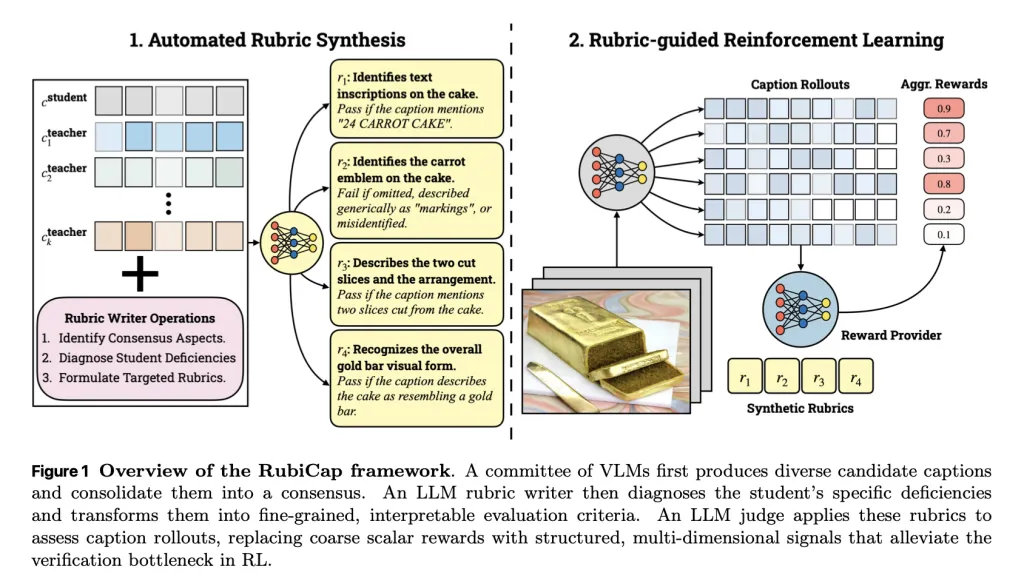
Οι πυκνοί λεζάντες εικόνων είναι κρίσιμοι για την πολλαπλή ευθυγράμμιση στην προεκπαίδευση γλώσσας όρασης και τη δημιουργία κειμένου σε εικόνα, αλλά η κλιμάκωση σχολιασμών ποιότητας ειδικού είναι απαγορευτικά δαπανηρή. Ενώ οι συνθετικές λεζάντες μέσω μοντέλων ισχυρής γλώσσας όρασης (VLM) είναι μια πρακτική εναλλακτική λύση, η εποπτευόμενη απόσταξη συχνά αποδίδει περιορισμένη ποικιλομορφία παραγωγής και ασθενή γενίκευση. Η ενισχυτική μάθηση (RL) θα μπορούσε να ξεπεράσει αυτούς τους περιορισμούς, αλλά οι επιτυχίες της μέχρι στιγμής έχουν συγκεντρωθεί σε επαληθεύσιμους τομείς που βασίζονται σε ντετερμινιστικά πούλια – μια πολυτέλεια που δεν είναι διαθέσιμη σε λεζάντες ανοιχτού τύπου.
Έχοντας αυτό υπόψη, πρότειναν ένα νέο πλαίσιο για την αντιμετώπιση αυτών των περιορισμών, το οποίο ακολούθησε μια ενδιαφέρουσα προσέγγιση.
Δείξαν τυχαία 50.000 εικόνες από δύο σετ δεδομένων εκπαίδευσης, το PixMoCap και το DenseFusion-4V-100K.
Για κάθε εικόνα, το σύστημα δημιούργησε πολλές επιλογές λεζάντας χρησιμοποιώντας ένα σύνολο υπαρχόντων μοντέλων γλώσσας όρασης, συμπεριλαμβανομένων των Gemini 2.5 Pro, GPT-5, Qwen2.5-VL-72B-Instruct, Gemma-3-27B-IT και Qwen3-VL-30B-A3B-Instruct.
Την ίδια στιγμή, το μοντέλο που εκπαιδεύτηκε στο RubiCap δημιούργησε τη δική του λεζάντα για αυτήν την εικόνα.
Στη συνέχεια, η RubiCap χρησιμοποίησε το Gemini 2.5 Pro για να:
- Αναλύστε την εικόνα μαζί με τους υποψηφίους λεζάντες και το αποτέλεσμα του ίδιου του μοντέλου.
- Προσδιορίστε τι συμφώνησαν τα μοντέλα και τι χάθηκε ή παραποιήθηκε.
- Μετατρέψτε το σε ξεκάθαρα κριτήρια για να κρίνετε τις λεζάντες.
Μετά από αυτό, ο Qwen2.5-7B-Instruct χρησίμευσε ως κριτής, βαθμολογώντας τους υπότιτλους σε κάθε κριτήριο για να παράγει το σήμα ανταμοιβής που χρησιμοποιήθηκε για την εκπαίδευση.
Ως αποτέλεσμα, το μοντέλο έλαβε πιο ακριβή, δομημένη ανατροφοδότηση σχετικά με το τι πρέπει να διορθώσει, οδηγώντας σε πιο ακριβείς λεζάντες χωρίς να βασίζεται σε μία μόνο «σωστή» απάντηση.
Όταν ειπώθηκαν και έγιναν όλα, οι ερευνητές παρήγαγαν τρία μοντέλα: RubiCap-2B, RubiCap-3B και RubiCap-7B, με 2 δισεκατομμύρια, 3 δισεκατομμύρια και 7 δισεκατομμύρια παραμέτρους, αντίστοιχα.
Και σε σύγκριση με τις τρέχουσες προσεγγίσεις, τα πήγαν εκπληκτικά καλά, ξεπερνώντας τα μοντέλα με έως και 72 δισεκατομμύρια παραμέτρους.
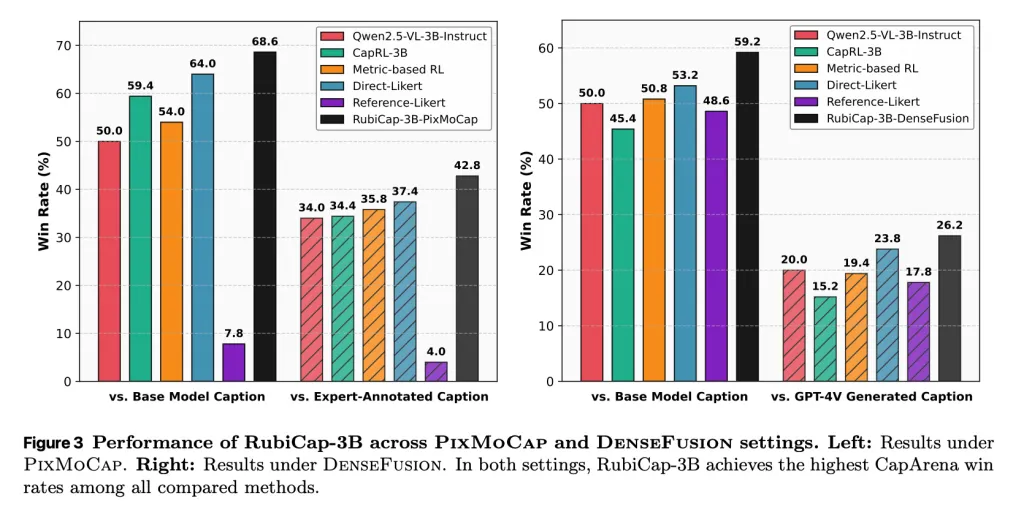
Από τη μελέτη:
Σε εκτεταμένα σημεία αναφοράς, το RubiCap επιτυγχάνει τα υψηλότερα ποσοστά κέρδους στο CapArena, ξεπερνώντας την απόδοση της εποπτευόμενης απόσταξης, των προηγούμενων μεθόδων RL, των σχολιασμών από τον άνθρωπο και των επαυξημένης απόδοσης GPT-4V. Στο CaptionQA, επιδεικνύει ανώτερη απόδοση λέξεων: το μοντέλο μας 7B ταιριάζει με το Qwen2.5-VL-32B-Instruct και το μοντέλο 3B ξεπερνά το αντίστοιχο 7B. Είναι αξιοσημείωτο ότι η χρήση του συμπαγούς RubiCap-3B ως υπότιτλου παράγει ισχυρότερα προεκπαιδευμένα VLM από αυτά που εκπαιδεύονται σε υπότιτλους από ιδιόκτητα μοντέλα.
Και
Σε μια τυφλή αξιολόγηση κατάταξης, το RubiCap-7B κερδίζει το υψηλότερο ποσοστό αναθέσεων κατάταξης-1 μεταξύ όλων των μοντέλων—συμπεριλαμβανομένων των 72B και 32B border—επιτυγχάνοντας τη χαμηλότερη ποινή παραισθήσεων και την ισχυρότερη ακρίβεια.
Σε περίπτωση που το χάσατε αυτό, οι ερευνητές παρατήρησαν ότι το μικρότερο μοντέλο 3 δισεκατομμυρίων παραμέτρων ξεπέρασε το μεγαλύτερο αντίστοιχό του σε ορισμένα σημεία αναφοράς, υποδηλώνοντας ότι ένα ισχυρό, πυκνό μοντέλο υπότιτλων εικόνων δεν απαιτεί απαραίτητα τεράστια κλίμακα για να προσφέρει αποτελέσματα υψηλής ποιότητας.
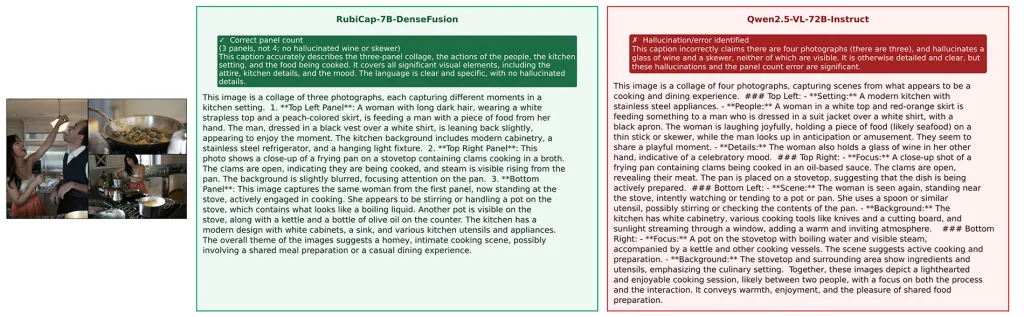
Ακολουθούν ορισμένες συγκρίσεις υπότιτλων μεταξύ RubiCap-7B-DenseFusion και Qwen2.5-VL-7B-Instruct:



Για να μάθετε περισσότερα σχετικά με τη μελέτη, συμπεριλαμβανομένης μιας εις βάθος ματιάς στους τεχνικούς της όρους, ακολουθήστε αυτόν τον σύνδεσμο.
Αξίζει να το δείτε στο Amazon
![]()
![]()
FTC: Χρησιμοποιούμε συνδέσμους θυγατρικών που κερδίζουν αυτόματα εισόδημα. Περισσότερο.

Via: 9to5mac.com